Hi, I am Sneha Gathani
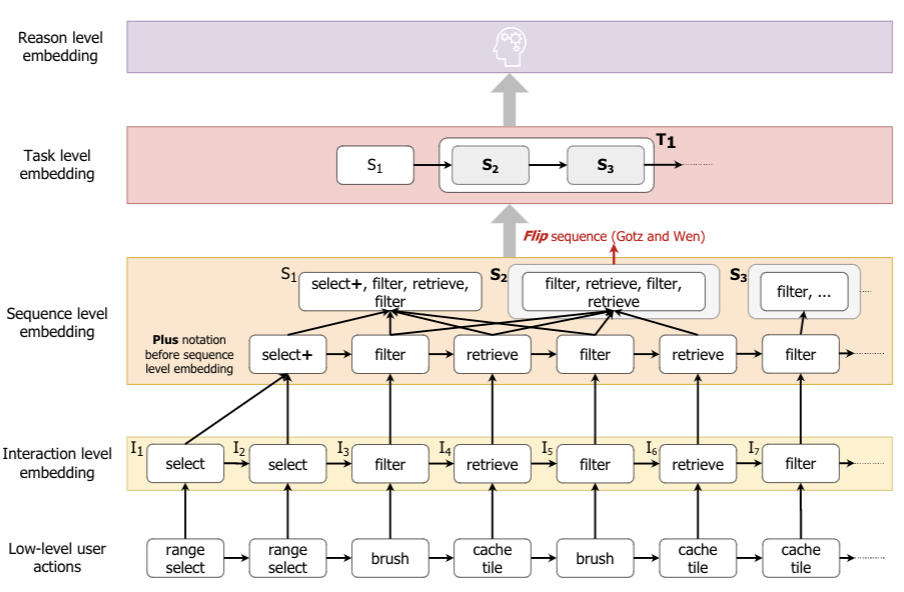
I am a 2nd year PhD student advised by Prof. Zhicheng Liu in the Human-Data Interaction Group at the University of Maryland, College Park (UMD). My research interests lie in the space of interested in the space of interactive visual data-driven decision-making systems, visual systems fostering trust in AI models, and Human-Centered AI.
I graduated with a Master's in Computer Science from UMD in May 2020. During Master's, I worked with Prof. Leilani Battle in the BAttle Data Lab (BAD Lab) in the intersection of Data Visualization, Databases and HCI.
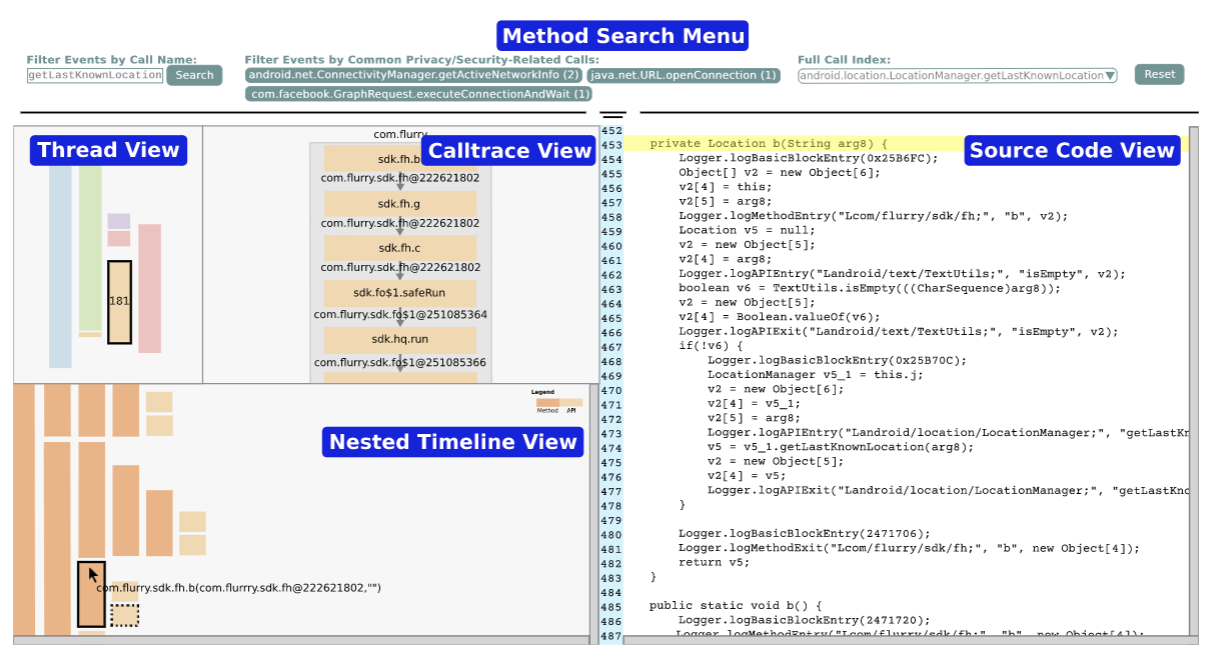
Over Masters and PhD, I have also gathered experience in the areas of database manaagement systems, computer graphics, computer vision and machine learning. Prior to grad school, I completed my Bachelors in Computer Engineering from University of Pune, India with a specialization in Computer Science.
News
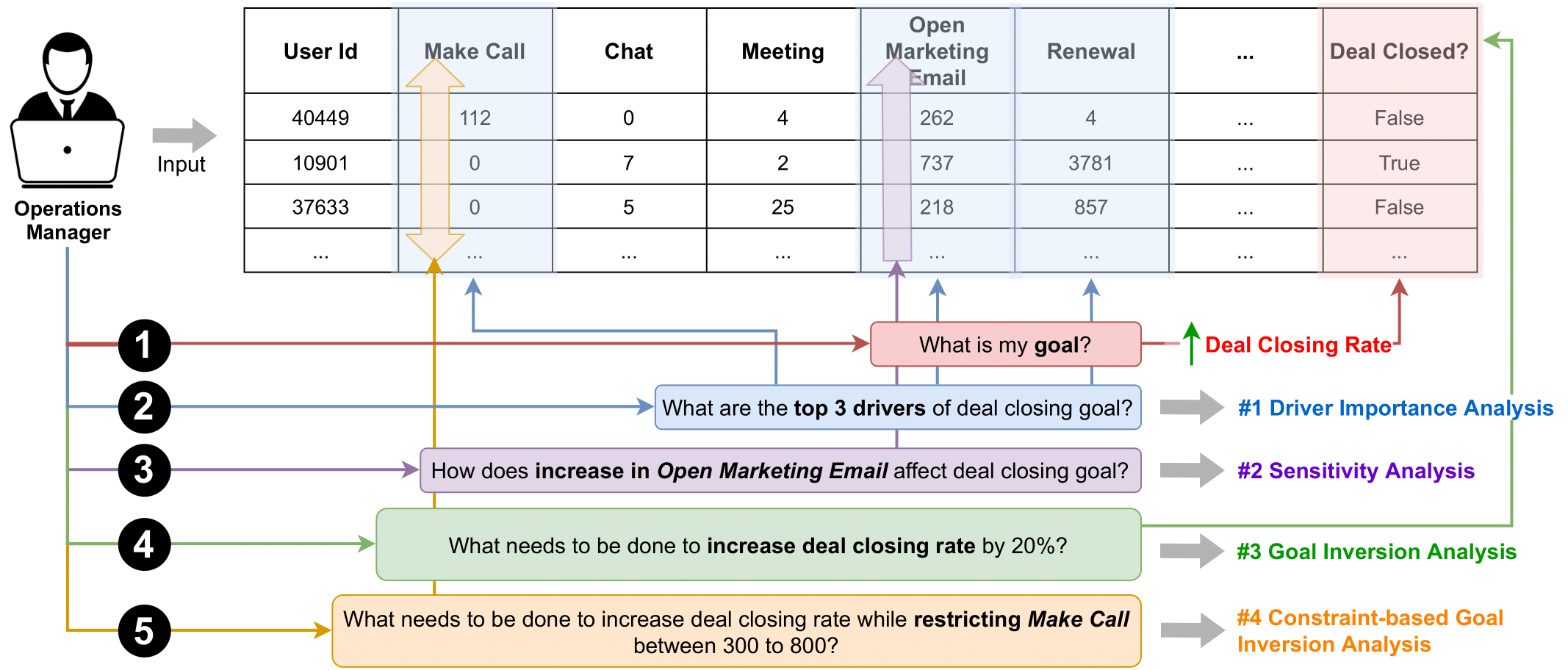
October 2021 My summer research work at Sigma Computing Inc. is accepted at CIDR 2022 as a full paperOctober 2021 Another summer research work at Sigma Computing Inc. is accepted at CIDR 2022 as a 1-page abstract
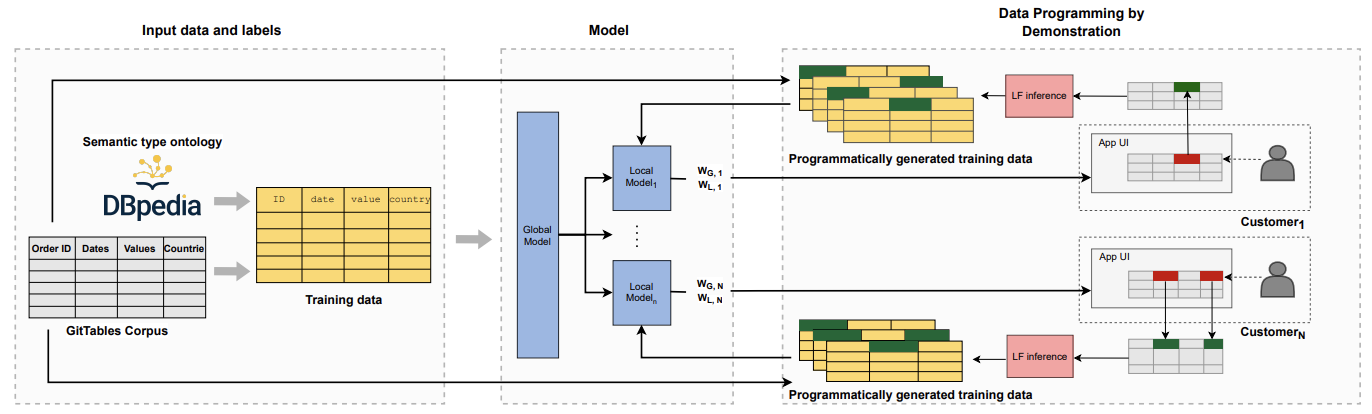
August 2021 I am continuing my summer intern at Sigma Computing Inc. with Çağatay Demiralp through the Fall semester